Conversión de documentos
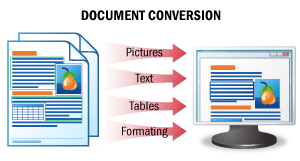
El resultado de este escenario es una versión editable de un documento.
En este escenario, se reconocen las imágenes de los documentos conservando todo el formato original, y los datos se guardan en un formato de archivo editable. Como resultado, se obtienen versiones editables de los documentos, que pueden revisarse fácilmente para detectar errores y modificarse.
Consulte Conversión de documentos para obtener más información.
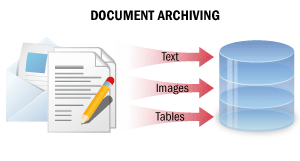
En este escenario de procesamiento, los documentos en papel se convierten en copias digitales no editables que contienen toda la información del documento en un formato de búsqueda. Como resultado de dicho procesamiento, las copias digitales de los documentos pueden localizarse fácilmente en un archivo electrónico mediante búsqueda de texto completo, los fragmentos de texto pueden copiarse, y los documentos pueden enviarse por correo electrónico o imprimirse.
Consulte Archivado de documentos para obtener más información.
Captura de datos
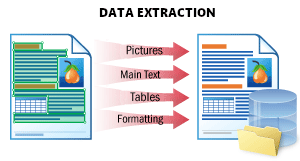
Este escenario se utiliza para extraer todos los datos posibles de un documento y almacenarlos de forma estructurada.
El resultado es un archivo JSON que representa la estructura del documento. Almacena todos los objetos del documento: texto impreso y escrito a mano, tablas, códigos de barras, marcas de verificación e imágenes con su ubicación y atributos. Este formato es ideal para su procesamiento posterior, para almacenar datos en una base de datos o para integrarlo con otra aplicación.
Consulte Extracción de datos para obtener más información.
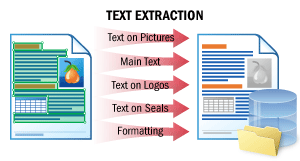
Este escenario permite extraer el texto principal de un documento y los textos de logotipos, sellos y otros elementos distintos del cuerpo del texto.
Se conserva el orden natural del texto, «como lo leería una persona». Luego puede enviar los documentos a motores de procesamiento de lenguaje natural (NLP) de su lado, por ejemplo, para resumirlos rápidamente, buscar información confidencial o someterlos a un análisis de sentimiento.
Consulte Extracción de texto para obtener más información.
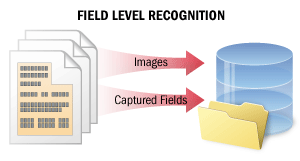
En el caso del reconocimiento a nivel de campo, se reconocen fragmentos breves de texto para capturar datos de determinados campos. La calidad del reconocimiento es crucial en este escenario.
Este escenario también puede utilizarse como parte de escenarios más complejos en los que se extraen datos relevantes de los documentos (por ejemplo, para capturar datos de documentos en papel en sistemas de información y bases de datos o para clasificar e indexar documentos automáticamente en sistemas de gestión documental).
En este escenario, el sistema reconoce varias líneas de texto solo en algunos campos, o bien el texto completo de una imagen pequeña. El sistema calcula un nivel de certeza para cada carácter reconocido. Estos niveles de certeza pueden utilizarse posteriormente al comprobar los resultados del reconocimiento. Además, el sistema puede almacenar múltiples variantes de reconocimiento de palabras y caracteres del texto, que posteriormente pueden utilizarse en algoritmos de votación para mejorar la calidad del reconocimiento.
Consulte Reconocimiento a nivel de campo para obtener más información.
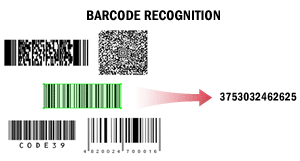
En este escenario, ABBYY FineReader Engine se utiliza para leer códigos de barras. Puede ser necesario leer códigos de barras, por ejemplo, para separar documentos automáticamente, para procesar documentos mediante un Document Management System o para indexarlos y clasificarlos.
Este escenario puede utilizarse como parte de otros escenarios. Por ejemplo, los documentos escaneados con escáneres de producción de alta velocidad pueden separarse mediante códigos de barras, o los documentos preparados para su almacenamiento a largo plazo pueden incorporarse a sistemas de archivado Document Management System en función de los valores de sus códigos de barras.
Al extraer códigos de barras de textos, el sistema puede detectar todos los códigos de barras o solo los códigos de barras de un determinado tipo con un determinado valor. El sistema puede obtener el valor de un código de barras y calcular su suma de comprobación.
Los valores de los códigos de barras reconocidos pueden guardarse en los formatos más adecuados para su posterior procesamiento, por ejemplo, en TXT.
Consulte Reconocimiento de códigos de barras para obtener más información.
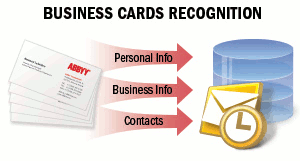
Las tarjetas de visita contienen información comercial sobre una empresa o una persona. Las tarjetas de visita pueden incluir el nombre de la persona, la empresa, números de teléfono, fax, correo electrónico, direcciones de sitios web e información similar. Puede que necesite capturar esta información de tarjetas de visita en papel y guardarla en formato electrónico. Puede tratarse de una libreta de direcciones electrónica de un teléfono móvil, un cliente de correo electrónico o cualquier otro sistema de almacenamiento de datos. Por ejemplo, las tarjetas de visita suelen enviarse por correo electrónico o a través de la red en formato vCard.
Consulte Reconocimiento de tarjetas de visita para obtener más información.
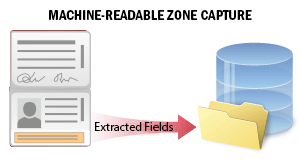
Los documentos oficiales de viaje o identidad de muchos países contienen una zona de lectura mecánica (MRZ) que permite procesar los datos del documento con mayor precisión.
Este escenario se utiliza para extraer datos de una zona de lectura mecánica en documentos de identidad durante los procesos de incorporación de clientes o verificación. El sistema reconoce la MRZ en la imagen del documento y extrae sus datos. Los datos extraídos contienen varios campos con información personal del documento y de su titular (tipo de documento y fecha de caducidad, nombre y apellidos del titular del documento, etc.). Puede buscar en los campos, verificar los datos y guardarlos en un archivo externo para su posterior procesamiento.
Consulte Captura de la zona de lectura mecánica para obtener más detalles.
Otros

En este escenario, ABBYY FineReader Engine se utiliza en un “equipo de escaneo”, que digitaliza imágenes y las guarda como archivos.
Este escenario puede utilizarse como parte de otros escenarios en la etapa preliminar del procesamiento de documentos, es decir, para obtener versiones electrónicas de los documentos para su posterior procesamiento. Algunos ejemplos de uso incluyen escanear documentos con fines de archivo, obtener versiones editables de documentos y extraer información relevante de ellos.
Los documentos en papel se escanean y las imágenes se guardan en un formato electrónico, lo que permite obtener versiones electrónicas de alta calidad de sus documentos impresos.
Consulte Escaneo para obtener más detalles.
La tarea de clasificación de documentos consiste en asignar un documento a una de las categorías definidas por el usuario. Es posible que tenga que trabajar con un flujo de documentos compuesto por documentos de varios tipos, por ejemplo, contratos, facturas y recibos. Debe identificar el tipo de cada documento. Por ejemplo, puede que quiera ordenar los documentos en distintas carpetas o cambiarles el nombre según su tipo. Esto puede hacerse automáticamente con un sistema previamente entrenado.
El aspecto principal de este escenario es que usted sabe qué tipos de documentos va a procesar. ABBYY FineReader Engine puede clasificar documentos por su apariencia o por su contenido.
Consulte Clasificación de documentos para obtener más detalles.

Al trabajar con documentos en papel, necesita encontrar y corregir errores o cambios realizados intencionadamente.
Este escenario se utiliza para comparar documentos de especial importancia, como contratos y documentación bancaria, con sus copias. El resultado de la comparación contiene información sobre las diferencias en el tipo de contenido (solo texto), el tipo de modificación (eliminado, insertado o modificado) y su ubicación en el original y la copia. Puede obtener la lista de diferencias detectadas o la región de cualquier cambio, y guardar el resultado de la comparación en un archivo externo para su posterior procesamiento o almacenamiento a largo plazo.
Consulte Document Comparison para obtener más detalles.