Antes de comenzar
- Abra la actividad “Sick Note DE” en el Activity Editor.
- Seleccione uno de los documentos del conjunto de documentos.
- Asegúrese de que el modo avanzado para las propiedades del elemento esté habilitado. Para activar o desactivar este modo, haga clic en el icono en el panel Properties.
- Todos los documentos cargados han pasado por un prerreconocimiento, y es útil ver qué objetos se encontraron en la imagen. Haga clic en el icono. Si no ve este icono debido al tamaño de su pantalla, haga clic en el icono y seleccione Recognized Words. Los objetos correspondientes se resaltarán en la imagen del documento. Puede alternar entre varios tipos de objetos resaltados en cualquier momento. Por ejemplo, cambiar a Recognized Lines puede ser útil al buscar párrafos, y cambiar a Separators facilitará la configuración de un elemento de búsqueda Separator.
- Si un elemento de búsqueda está fuera del área de búsqueda, no se encontrará. Habilite la opción Show search area en el menú contextual de la imagen del documento. El área de búsqueda de cada elemento se resaltará en verde cuando evalúe los resultados de coincidencia.
Extracción de los datos del paciente
- Haga clic en Create Element y seleccione el elemento Group en la lista desplegable. Cambie su nombre a “PatientDataArea”.
- Un nuevo elemento de búsqueda de grupo se establece como obligatorio de forma predeterminada. Si no se encuentra un elemento obligatorio, el Activity Editor genera un error y la coincidencia se aborta. Este escenario permite omitir actividades si no son adecuadas para un determinado documento. Sin embargo, en este tutorial estamos creando una actividad para extraer datos de todos los documentos entrantes, por lo que queremos que el grupo sea opcional. En la sección Under what conditions, cambie el valor Element is a Optional.
- Queremos encontrar el párrafo que contiene el nombre y la dirección del paciente. En los documentos alemanes, el párrafo que buscamos siempre se encuentra en el campo con la etiqueta “Name, Vorname … ”. Necesitamos localizar este texto en el documento y usarlo como referencia para buscar los datos que queremos extraer.
a. Las palabras clave pueden localizarse con el elemento de búsqueda Static Text. Haga clic en Create Element y seleccione el elemento Static Text en la lista desplegable. Cambie su nombre a “kwPatientTitle”.
b. Introduzca el texto “Name, Vorname” en el campo Text to find del panel Properties.
c. Haga clic en Match. Cuando finalice el procesamiento, verá el Tree of Hypotheses debajo del documento. Asegúrese de que Advanced Designer haya encontrado correctamente el texto estático deseado. Un punto verde junto al nombre del elemento indica que se encontró correctamente un elemento correspondiente en el documento. Si hace clic en el nombre del elemento en el Tree of Hypotheses, verá un marco violeta alrededor de la región correspondiente en el documento.
Si no se encuentra un elemento, verá un punto naranja junto a su nombre y un marco naranja alrededor de la imagen del documento. Tenga en cuenta que la calidad de la hipótesis de un elemento afecta al estado de los elementos siguientes en la cadena y a la calidad general de una cadena. Puede encontrar información detallada sobre la calidad de la hipótesis en la documentación.
- Ahora busquemos el límite inferior de la celda que contiene el nombre y la dirección del paciente. Lo haremos usando un elemento Separator.
a. Agregue un elemento Separator al grupo y llámelo “SeparatorBottom”. Establezca su longitud mínima en 200.
b. Haga clic con el botón derecho en el elemento y seleccione Match Element en el menú contextual. Verá que el Tree of Hypotheses contiene muchos puntos verdes. Corresponden a diferentes separadores que cumplen los criterios de búsqueda. Puede hacer clic en cada punto para ver el objeto correspondiente en la imagen.
c. Para acotar los criterios de búsqueda, especifique el área de búsqueda para el separador. Haga clic en Match para encontrar el elemento “kwPatientTitle” que se usará como elemento ancla. En la sección Where to search del panel Properties, haga clic en Draw on Image. Seleccione el elemento “kwPatientTitle” en el documento y haga clic en el icono de flecha hacia abajo para especificar el área de búsqueda debajo de la palabra clave y en el icono más cercano para buscar el separador más próximo a la palabra clave. Puede encontrar una descripción detallada de los elementos ancla en la documentación.
d. Haga clic en Match y compruebe que Advanced Designer haya encontrado el separador debajo del elemento “kwPatientTitle”. Puede comprobar la hipótesis de cada elemento haciendo clic en su nombre en la sección Tree of Hypotheses. - Una etiqueta y un separador son elementos de referencia fiables para los datos del paciente. Sin embargo, si la calidad de impresión es demasiado baja, existe la posibilidad de que el texto de la etiqueta no se reconozca o que no se encuentre el separador. Para garantizar buenos resultados de extracción, buscaremos un párrafo situado entre la etiqueta y el separador. Un párrafo es un bloque uniforme de texto, lo que significa que puede encontrarse correctamente incluso si no se encontraron algunos de los elementos de borde.
a. Cree un elemento de búsqueda Paragraph y llámelo “NameAddressParagraph”.
b. Cambie Text alignment a Left.
c. Los datos del paciente ocupan de dos a cinco líneas, así que especifique el Line count de 2 a 5.
d. Especifique el área de búsqueda para el párrafo. Esta vez debe usar el menú Add en la sección Where to search. El elemento debe estar ubicado debajo del elemento “kwPatientTitle” y encima del elemento “SeparatorBottom”.
e. Haga clic en Match. - Ahora queremos extraer los datos del paciente. Cree un nuevo elemento de grupo llamado “PatientGroup”.
- El nombre del paciente puede ocupar una o dos líneas. Para capturar varias instancias de un elemento, usaremos un grupo repetido.
a. Cree un elemento de búsqueda Repeating Group y llámelo “NameGroup”. Especifique 2 como el número máximo de repeticiones. Haga que el elemento sea opcional.
b. Queremos buscar las líneas que forman parte del párrafo “NameAddressParagraph”. Para especificar la región del elemento como área de búsqueda, haga clic en el icono del editor de código debajo de la imagen del documento y pegue el siguiente script en la sección Search Conditions del Code Editor:
d. El texto que buscamos puede contener letras mayúsculas y minúsculas, así como un conjunto de signos de puntuación que pueden aparecer en nombres. Configure dos conjuntos de caracteres por separado. El primer conjunto debe contener todas las letras latinas mayúsculas y minúsculas. Para agregar caracteres con signos diacríticos, cambie el subrango Unicode o pegue los caracteres directamente en el campo Selected characters.
e. El otro conjunto debe contener los siguientes signos de puntuación: ,-.()’. No queremos que la cadena contenga solo signos de puntuación, así que establezca Portion in text, % para el segundo conjunto en 40%. Esta propiedad define el porcentaje máximo permitido de caracteres de un determinado conjunto.
La configuración predeterminada permite que la cadena contenga hasta un 30% de caracteres no incluidos en ningún conjunto. Esto ayuda a encontrar cadenas incluso cuando algunos caracteres se reconocen incorrectamente o no están incluidos en el conjunto (como los caracteres con signos diacríticos). Puede ajustar esta configuración cambiando el valor de Allowed errors en el panel Properties.
g. Especifique el área de búsqueda para el elemento “NameLine”: debajo del elemento “kwPatientTitle” y lo más cerca posible de este.
h. Haga clic en Match y revise el Tree of Hypotheses. Verá que se encuentran dos cadenas de caracteres. Sin embargo, la segunda cadena contiene la dirección del paciente.
i. Para excluir la dirección de los resultados de búsqueda, comprobaremos si la primera cadena contiene tanto el nombre como el apellido. Esto se puede hacer agregando una sencilla condición de búsqueda mediante script. Seleccione el elemento de búsqueda “NameLine” y abra el editor de código Search Conditions.
j. Suponemos que la primera línea contiene un nombre completo si contiene una coma y un espacio en blanco. Si contiene un nombre completo, no queremos buscar una segunda instancia del grupo repetido. Pegue el siguiente script en el editor:
- El nombre del paciente extraído en el paso 7 se asignará al campo “Name”. También extraeremos y asignaremos la dirección del paciente.
a. Dentro de “PatientGroup”, cree un elemento de búsqueda Character String llamado “Address” con la misma configuración de conjunto de caracteres que el elemento “NameLine”.
b. Especifique el área de búsqueda del elemento mediante código: la dirección debe estar ubicada debajo de “NameLine” o, en caso de que no se haya encontrado este elemento, debajo de la primera línea del elemento “NameAddressParagraph”.
d. Haga clic en Match. Así es como debe verse la estructura de elementos de búsqueda:
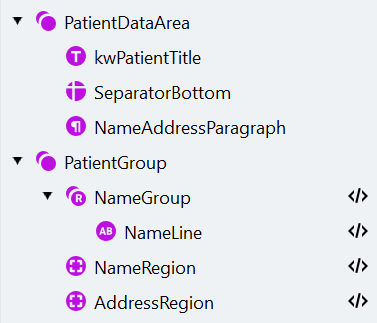
- Abra el cuadro de diálogo Manage Fields, cree los campos correspondientes y asígnelos a los elementos de búsqueda de la siguiente manera:
| Name | Type | Search element |
|---|---|---|
| Name | Campo de texto en el grupo “Patient” | NameLine |
| Address | Campo de texto en el grupo “Patient” | Address |
- Elimine los elementos de búsqueda que se crearon automáticamente para los nuevos campos.
Extracción del tipo de baja médica
- Cree un elemento Group llamado “TypeOfSickNoteGroup”. Haga que el elemento sea opcional.
- Para almacenar la información sobre ambas marcas de verificación, cree un elemento de búsqueda Repeating Group y llámelo “PrimaryGroup”.
a. Es una buena idea restringir el área de búsqueda para el grupo de elementos. Especifique el área de búsqueda mediante código: a la derecha del elemento “PatientGroup” y por encima del elemento “DoctorAreaGroup” (que se creará más adelante). **Nota: **Especifique siempre la condición “Exists” cuando utilice elementos futuros.
c. Cree un elemento de búsqueda Object Collection llamado “Checkmark” con la siguiente configuración: Type:
Checkmark, Checkmark state: Checked, Minimum height: 10, Maximum width: 20, Maximum height: 20. Especifique que el elemento está ubicado a la izquierda del elemento “kwPrimary” y lo más cerca posible de este. d. Haga clic en Match.
- Copie y pegue el grupo “PrimaryGroup”. Cambie el nombre del grupo copiado a “SecondaryGroup”. Este grupo será obligatorio.
- Edite el “SecondaryGroup”.
a. Cambie el nombre del elemento “kwPrimary” a “kwSecondary” y establezca el texto a buscar en “Folgebescheinigung”. Especifique el área de búsqueda: debajo del elemento “kwPrimary” del “PrimaryGroup”.
b. Especifique el área de búsqueda para el elemento “Checkmark”: a la izquierda de “kwSecondary” y lo más cerca posible de este.
c. El elemento de búsqueda Object Collection encuentra una colección de todos los objetos adecuados dentro del área de búsqueda. Si las marcas de verificación están ubicadas en la misma línea, el elemento “Checkmark” del “SecondaryGroup” también puede encontrar la marca de verificación primaria. Para evitarlo, excluya la marca de verificación primaria (elemento “Checkmark” del “PrimaryGroup”) del área de búsqueda para el elemento “Checkmark” del “SecondaryGroup”.
d. Haga clic en Match.
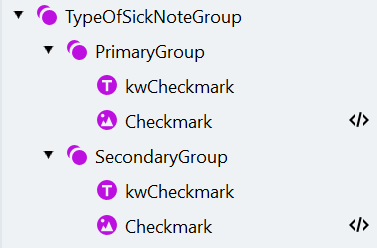
- Abra la ventana Manage Fields, cree los campos correspondientes y asígnelos a los elementos de búsqueda de la siguiente manera:
| Name | Type | Search element |
|---|---|---|
| Type of Sick Note | Checkmark group | |
| Primary | Checkmark in the “Type of Sick Note” checkmark group | PrimaryGroup -> Checkmark |
| Secondary | Checkmark in the “Type of Sick Note” checkmark group | SecondaryGroup -> Checkmark |
- Elimine los elementos de búsqueda que se crearon automáticamente para los nuevos campos.
Extracción de los datos del médico
- Cree un elemento Group llamado “DoctorAreaGroup”. Haga que el elemento sea opcional.
- El cuadro que vamos a buscar contiene una etiqueta. Para encontrarla, cree un elemento Static Text llamado “kwDoctorTitle” (texto a buscar: “Unterschrift des Arztes”).
- Dentro del grupo “DoctorAreaGroup”, cree otro grupo llamado “DataArea”.
- El cuadro que contiene la información y la firma del médico es una combinación de cuatro separadores. Están ubicados alrededor del elemento “kwDoctorTitle”. Sin embargo, debemos configurar los elementos de forma que permitan al programa encontrarlos incluso si no se encontró el elemento “kwDoctorTitle”. En el grupo “DataArea”, cree cuatro elementos de búsqueda Separator con las siguientes propiedades:
| Name | Orientation | Minimum length | Search area |
|---|---|---|---|
SeparatorRight | Vertical | 180 | A la derecha de “kwDoctorTitle”, más cercano al borde derecho de la página |
SeparatorLeft | Vertical | 180 | A la izquierda de “kwDoctorTitle”, a la izquierda de “SeparatorRight” (en caso de que no se haya encontrado “kwDoctorTitle”), más cercano a “SeparatorRight”, por debajo de “SeparatorRight” (haga clic en el icono a la derecha del nombre del separador y seleccione Top Boundary of Region), excluir “SeparatorRight” |
SeparatorBottom | Horizontal | 200 | Por debajo de “kwDoctorTitle” (con un ajuste de -10 puntos), a la derecha de “SeparatorLeft”, a la izquierda de “SeparatorRight”, más cercano al borde inferior de la página (esta configuración será útil en caso de que no se haya encontrado “kwDoctorTitle”) |
SeparatorTop | Horizontal | 200 | Por encima de “kwDoctorTitle”, a la derecha de “SeparatorLeft”, más cercano a “TypeOfSickNoteGroup”, excluir “SeparatorBottom” |
- Podríamos especificar manualmente el área de búsqueda para la firma y la información del médico con respecto a los separadores encontrados. En lugar de hacerlo, crearemos un elemento Region que corresponda al área delimitada por los separadores. Cree un elemento de búsqueda Region llamado “BoxRegion” y especifique el área de búsqueda: a la izquierda de “SeparatorRight”, a la derecha de “SeparatorLeft”, por encima de “SeparatorBottom” y por debajo de “SeparatorTop”.
- Cree un nuevo grupo llamado “DoctorGroup”.
- Para localizar la firma del médico, cree un elemento Object Collection con la siguiente configuración dentro de “DoctorGroup”:
| Property | Value |
|---|---|
| Name | Signature |
| Type | Picture |
| Minimum width | 15 |
| Minimum height | 15 |
| Maximum width | 600 |
| Maximum height | 350 |
| Search Conditions section of the Code Editor | La firma puede estar ubicada parcialmente fuera del cuadro. Para encontrar la imagen completa, expandiremos el área de búsqueda en 100 puntos en cada dirección: RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect.GetInflated(100dot,100dot); |
- Para extraer la información de texto del cuadro, cree un elemento Paragraph con la siguiente configuración:
| Property | Value |
|---|---|
| Name | DoctorInformation |
| Maximum line count | 6 |
| Search area | Por encima de “kwDoctorTitle”, excluir “Signature” |
| Search Conditions section of the Code Editor | RSA: DoctorAreaGroup.DataArea.BoxRegion.Rect; |
- Haga clic en Match y asegúrese de que los elementos se encuentren correctamente.
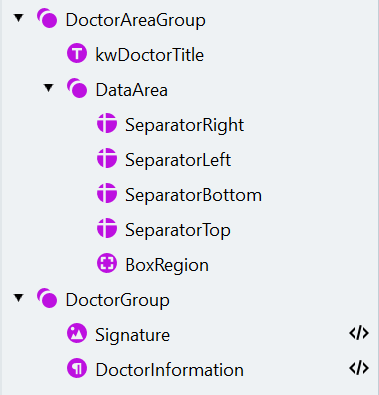
- Abra el cuadro de diálogo Manage Fields, cree los campos correspondientes y asígnelos a los elementos de búsqueda de la siguiente manera:
| Name | Type | Search element |
|---|---|---|
| Doctor Information | Campo de texto en el grupo “Doctor” | DoctorInformation |
| Signature | Campo de imagen en el grupo “Doctor” | Signature |
- Elimine los elementos de búsqueda que se crearon automáticamente para los nuevos campos.