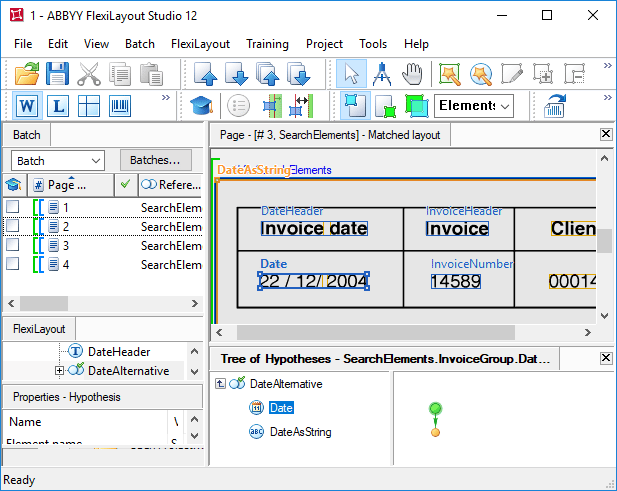
Par souci de simplicité, un document d’une seule page est utilisé dans cet exemple.
La première ligne du code (let Header = InvoiceGroup.DateHeader;) simplifie le code en définissant la variable Header et en lui affectant la valeur de l’élément DateHeader.
Pour définir la zone de recherche de l’élément DateAsString comme un tableau de rectangles, au lieu d’appeler RestrictSearchArea (Date.Rect), dupliquez le code correspondant de la section relations avancées de pré-recherche de l’élément Date.
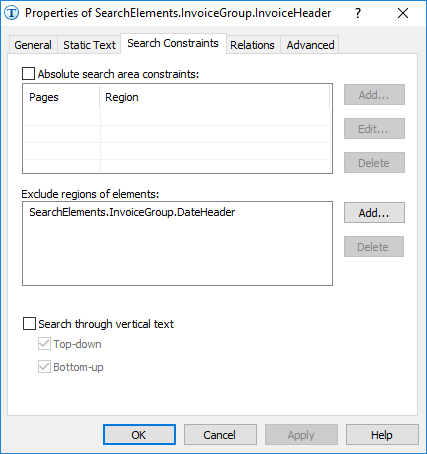
Si nous avions commencé à créer le FlexiLayout non pas avec le nom DateHeader mais avec le nom InvoiceHeader, nous n’aurions pas pu utiliser la fonction Exclude, car cette fonction ne peut exclure que des éléments situés plus haut que l’élément actuel dans l’arborescence du projet.
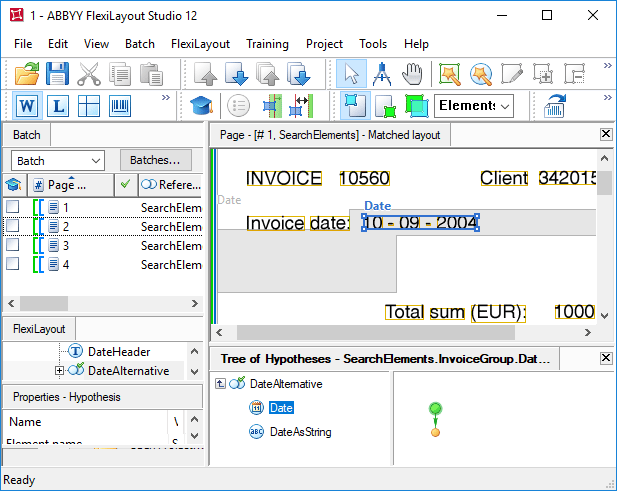
 Une fois le FlexiLayout mis en correspondance, nous constatons que notre méthode a échoué sur la page 2, car l’intitulé du champ de date y est très parasité et n’a pas été détecté. Sur cette page, la contrainte spécifiée dans la fonction Nearest est vraie pour les deux chaînes « Invoice », car elles se trouvent au même niveau. Et comme la qualité de reconnaissance des chaînes « Invoice » est bonne dans les deux cas, l’algorithme d’optimisation a généré une seule hypothèse au lieu de deux hypothèses distinctes. Malheureusement, cette hypothèse n’est pas correcte.
Pour détecter le champ « Numéro de facture », nous avons créé un élément de type Character String, nommé InvoiceNumber. Comme pour l’élément du champ de date, nous spécifions les contraintes de recherche du champ « Numéro de facture » dans la section relations avancées de pré-recherche. La zone de recherche de cet élément est un tableau de rectangles.
let Header = InvoiceGroup.InvoiceHeader;
if not Header.IsNull then
{ let rect1 = Rect (Header.Rect.Right, Header.Rect.Top-20dt,
PageRect.Right, Header.Rect.Bottom+20dt);
let rect2 = Rect (Header.Rect.Left - 200dt, Header.Rect.Bottom,
Header.Rect.Right + 150dt, Header.Rect.Bottom+200dt);
RectArray ar;
ar = RectArray( rect1 );
ar.Add( rect2 );
RestrictSearchArea( ar );
}
else
{ Above: PageRect.Top + PageRect.Height/2;
}
Nearest: Header;
Nous avons en outre ajouté une contrainte supplémentaire au code. Nous avons indiqué au programme que l’élément InvoiceNumber est le plus proche de l’élément correspondant à l’intitulé.
Après avoir exécuté la procédure de mise en correspondance, nous constatons que le champ « Numéro de facture » a été détecté incorrectement sur les pages 2 et 4. Il a également été détecté incorrectement sur la page 4, alors même que l’intitulé du champ avait été détecté correctement.
Une fois le FlexiLayout mis en correspondance, nous constatons que notre méthode a échoué sur la page 2, car l’intitulé du champ de date y est très parasité et n’a pas été détecté. Sur cette page, la contrainte spécifiée dans la fonction Nearest est vraie pour les deux chaînes « Invoice », car elles se trouvent au même niveau. Et comme la qualité de reconnaissance des chaînes « Invoice » est bonne dans les deux cas, l’algorithme d’optimisation a généré une seule hypothèse au lieu de deux hypothèses distinctes. Malheureusement, cette hypothèse n’est pas correcte.
Pour détecter le champ « Numéro de facture », nous avons créé un élément de type Character String, nommé InvoiceNumber. Comme pour l’élément du champ de date, nous spécifions les contraintes de recherche du champ « Numéro de facture » dans la section relations avancées de pré-recherche. La zone de recherche de cet élément est un tableau de rectangles.
let Header = InvoiceGroup.InvoiceHeader;
if not Header.IsNull then
{ let rect1 = Rect (Header.Rect.Right, Header.Rect.Top-20dt,
PageRect.Right, Header.Rect.Bottom+20dt);
let rect2 = Rect (Header.Rect.Left - 200dt, Header.Rect.Bottom,
Header.Rect.Right + 150dt, Header.Rect.Bottom+200dt);
RectArray ar;
ar = RectArray( rect1 );
ar.Add( rect2 );
RestrictSearchArea( ar );
}
else
{ Above: PageRect.Top + PageRect.Height/2;
}
Nearest: Header;
Nous avons en outre ajouté une contrainte supplémentaire au code. Nous avons indiqué au programme que l’élément InvoiceNumber est le plus proche de l’élément correspondant à l’intitulé.
Après avoir exécuté la procédure de mise en correspondance, nous constatons que le champ « Numéro de facture » a été détecté incorrectement sur les pages 2 et 4. Il a également été détecté incorrectement sur la page 4, alors même que l’intitulé du champ avait été détecté correctement.
Comme autre possibilité (pour les images du projet actuel) au lieu de Nearest: Header;, nous pourrions écrire NearestY: Header.Rect.YCenter;, afin d’indiquer au programme que le champ recherché est, verticalement, le plus proche du centre de l’intitulé. Cela pourrait résoudre le problème de détection incorrecte du champ « Numéro de facture » sur la page 4. Mais cela n’aide pas sur la page 5, car le champ recherché est détecté dans le champ de date après la détection incorrecte de l’intitulé « Numéro de facture ».
Lorsque vous choisissez les paramètres qui définissent les limites de l’intervalle, vous devez veiller à ce qu’ils (en particulier lorsqu’il y a plusieurs vérifications d’éléments avec la fonction FuzzyQuality) ne pénalisent pas l’hypothèse correcte au point que sa qualité finale devienne inférieure à celle d’une hypothèse nulle. Si la qualité de toutes les hypothèses (y compris la bonne) est inférieure à la valeur de qualité d’une hypothèse nulle, l’hypothèse nulle peut être sélectionnée, c’est-à-dire que l’élément ne sera pas détecté.
 (a)
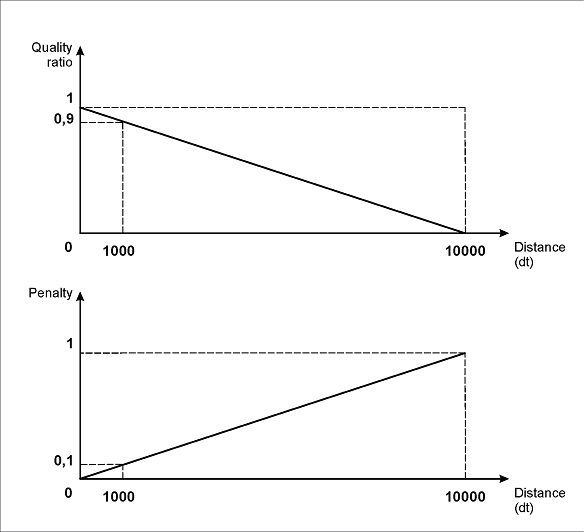
La ligne *FuzzyQuality: 500dt - Width, {0,0,0,100000}dt; signifie que le programme prend en compte l’écart entre la largeur de l’objet détecté et la valeur hypothétique de 500dt. Autrement dit, la différence (500dt - Width) est calculée, puis le programme vérifie si cette différence appartient à l’intervalle {0, 0, 0, 100000}*dt. Plus l’objet est étroit, plus la pénalité est élevée ; ainsi, les numéros de facture plus longs seront privilégiés. Cette contrainte peut être utilisée si l’image contient du bruit. Si le bruit est reconnu comme un caractère de l’alphabet spécifié (comme on peut le voir, par exemple, à la page 2), son hypothèse doit être pénalisée afin de l’exclure de l’analyse ultérieure.
(a)
La ligne *FuzzyQuality: 500dt - Width, {0,0,0,100000}dt; signifie que le programme prend en compte l’écart entre la largeur de l’objet détecté et la valeur hypothétique de 500dt. Autrement dit, la différence (500dt - Width) est calculée, puis le programme vérifie si cette différence appartient à l’intervalle {0, 0, 0, 100000}*dt. Plus l’objet est étroit, plus la pénalité est élevée ; ainsi, les numéros de facture plus longs seront privilégiés. Cette contrainte peut être utilisée si l’image contient du bruit. Si le bruit est reconnu comme un caractère de l’alphabet spécifié (comme on peut le voir, par exemple, à la page 2), son hypothèse doit être pénalisée afin de l’exclure de l’analyse ultérieure.
La valeur de 500dt est choisie par examen visuel, en supposant que la longueur de la string dans le champ “Numéro de facture” ne dépasse pas cette valeur. Les paramètres indiqués ici définissent que la pénalité maximale (0,005) correspondrait à une largeur nulle du champ “Numéro de facture”. Pour toute autre largeur comprise entre 0 et 500dt, les pénalités de qualité seraient plus faibles.
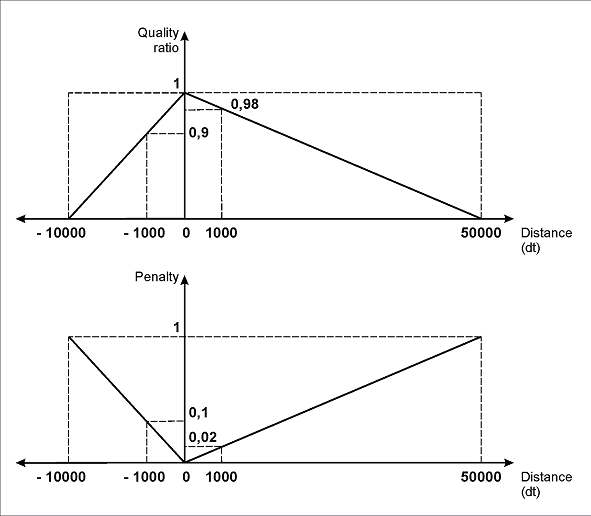 (b)
La ligne *FuzzyQuality: Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} dt; est identique à la précédente. Mais elle est réservée aux cas où le champ « Numéro de facture » se trouve au même niveau horizontal, voire légèrement au-dessus du champ du nom. Les pénalités y sont les mêmes pour tout décalage vertical. Les limites de l’intervalle sont définies selon la même logique, afin de privilégier les hypothèses qui trouvent le champ de données à droite de son nom. Cependant, le projet montre que ces paramètres n’ont pas empêché la détection correcte du numéro de facture même lorsqu’il était situé sous le nom (page 3).
Après la mise en correspondance de FlexiLayout avec toutes les pages, nous constatons que les deux champs recherchés ont bien été détectés.
En conclusion, nous pouvons dire que la fonction FuzzyQuality est plus efficace et plus souple que les fonctions du groupe Nearest, ce qui est particulièrement important pour le traitement de documents semi-structurés.
(b)
La ligne *FuzzyQuality: Rect.YCenter - InvoiceHeader.Rect.YCenter, {-10000,0,0,10000} dt; est identique à la précédente. Mais elle est réservée aux cas où le champ « Numéro de facture » se trouve au même niveau horizontal, voire légèrement au-dessus du champ du nom. Les pénalités y sont les mêmes pour tout décalage vertical. Les limites de l’intervalle sont définies selon la même logique, afin de privilégier les hypothèses qui trouvent le champ de données à droite de son nom. Cependant, le projet montre que ces paramètres n’ont pas empêché la détection correcte du numéro de facture même lorsqu’il était situé sous le nom (page 3).
Après la mise en correspondance de FlexiLayout avec toutes les pages, nous constatons que les deux champs recherchés ont bien été détectés.
En conclusion, nous pouvons dire que la fonction FuzzyQuality est plus efficace et plus souple que les fonctions du groupe Nearest, ce qui est particulièrement important pour le traitement de documents semi-structurés.